Research
Our group’s research focuses on Computer Vision, Machine Learning, and Human-in-the-Loop Computing with applications ranging from image based geolocalization to assistive technology for the visually impaired. Much of our work involves humans and machines working together to solve challenging problems involving fine grained categorization and perceptual organization. Follow the links below to learn about our project themes and see our publications in these areas.
Here are some themes and techniques that we currently work on:
Narrative Modeling.
 Whether through clustering or classification, machine learning provides flexible computational methods for inferring and constructing ontologies. Our group has explored such ontologies both in the context of multimodality (how images relate to text) and in the context of fine-grained categorization (how systems can attend to subtle image details important to humans).
Whether through clustering or classification, machine learning provides flexible computational methods for inferring and constructing ontologies. Our group has explored such ontologies both in the context of multimodality (how images relate to text) and in the context of fine-grained categorization (how systems can attend to subtle image details important to humans).
An culturally important domain of ontologies that remains largely unexplored in machine learning are narratives. Humans have for a long time narrated their observed shared realities, and used narratives as devices for sense making. Just as medieval societies populated their worlds with witches and monsters, our internet feed is constantly flooded by new “witches” and “monsters”. Designing algorithms that help people navigate the increased scale of online narratives becomes an urgent need to ground digital democracy.
At SØ(3), we aim to bridge this gap in two ways:
- Building a large-scale database for narrative annotation and live observation across time, combining citizen science with expert moderation from narratologists.
- Developing technologies that enable users to parse and annotate their political feeds in real time, empowering more informed forms of personal and collective sense-making.
Embeddings and Metric Learning.
![]() Understanding similarities between images is a key problem in computer vision. To measure the similarity between images, they are typically embedded in a feature vector space, in which their distance preserve the relative dissimilarity. These vector space representations are commonly used in applications such as image retrieval, classification or visualizations.
Understanding similarities between images is a key problem in computer vision. To measure the similarity between images, they are typically embedded in a feature vector space, in which their distance preserve the relative dissimilarity. These vector space representations are commonly used in applications such as image retrieval, classification or visualizations.
In our group, we are interested in many aspects of similarity learning. On one hand, we work on fundamental methods to learn similarity spaces. One the other hand, we work on applications of visual similarities in areas such as fine-grained categorization and recommendation systems.
Privacy and security.
 Massive data collection required for training deep neural networks presents serious privacy issues. Centralized collection of photos, speech, and video from millions of individuals is ripe with privacy risks.
Massive data collection required for training deep neural networks presents serious privacy issues. Centralized collection of photos, speech, and video from millions of individuals is ripe with privacy risks.
Ideally, the learning algorithms would protect the privacy of users’ training data, by guaranteeing that the output model generalizes away from the specifics of any individual user. However, established machine learning algorithms make no such guarantee, and private, sensitive training data can be recovered from models. A model may implicitly store some of its training data, and careful analysis of the model may therefore reveal sensitive information.
We aim to better understand vulnerabilities of machine learning models and to provide proper defense methods against adversarial attacks.
Visual Style
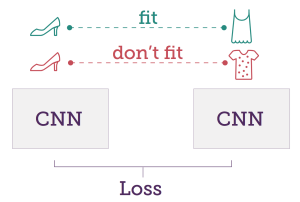 Style and content are two separate factors of an image. While most previous computer vision research has been focused on visual content (e.g., recognizing object categories), there is an increasing interest in understanding and manipulating visual style. At SE(3), we are mainly interested in two different but related domains: 1) Artistic style, and 2) Clothing style.
Style and content are two separate factors of an image. While most previous computer vision research has been focused on visual content (e.g., recognizing object categories), there is an increasing interest in understanding and manipulating visual style. At SE(3), we are mainly interested in two different but related domains: 1) Artistic style, and 2) Clothing style.
COCO.
 Common Objects in Context (COCO) is a database that aims to enable future research for object detection, instance segmentation, image captioning, and person keypoints localization.
Common Objects in Context (COCO) is a database that aims to enable future research for object detection, instance segmentation, image captioning, and person keypoints localization.
For more details, see mscoco
Assistive Technology.
 The contemporary urban environment is brimming with rich visual cues that provide valuable directional and informational content to sighted individuals. The goal of the this project is to make these visual cues universally accessible in a variety of real-world domains.
The contemporary urban environment is brimming with rich visual cues that provide valuable directional and informational content to sighted individuals. The goal of the this project is to make these visual cues universally accessible in a variety of real-world domains.
Text in Natural Images.
 Text in natural images carries rich and high-level information. Examples including text on product labels, receipts, and traffic signs. Reading text in images facilitates many real world applications, e.g. retrieving images, parsing product labels, translate foreign text (like the Google Translate app).
Text in natural images carries rich and high-level information. Examples including text on product labels, receipts, and traffic signs. Reading text in images facilitates many real world applications, e.g. retrieving images, parsing product labels, translate foreign text (like the Google Translate app).
The challenges of reading such text include handling the large variations in text and noisy backgrounds, detecting long lines of oriented text, and handling multi-lingual text, etc.
At SE(3), we are interested in two of the most fundamental and important problems of this topic: 1) Building large-scale datasets for training and evaluating algorithms; 2) Developing robust and flexible text detection and recognition algorithms.
Feature Detection and Matching.
 Feature detection and matching is an important task in many computer vision applications, such as structure-from-motion, image retrieval, object detection, and more. Challenges in this problem encompass identifying what features are, in a detection step, and further describing those features for other tasks such as feature matching. At SE(3), we are interested in developing better and more robust techniques in feature detection and description.
Feature detection and matching is an important task in many computer vision applications, such as structure-from-motion, image retrieval, object detection, and more. Challenges in this problem encompass identifying what features are, in a detection step, and further describing those features for other tasks such as feature matching. At SE(3), we are interested in developing better and more robust techniques in feature detection and description.
Generative Models.
 Learning generative models that can explain complex data distribution is a long-standing problem in machine learning research. At SE(3), we are particularly interested in image generation, which is extremely challenging due to the high dimensionality of data. Generative models of images are not only important for unsupervised feature learning, but also enable a wide range of commercial applications such as image editing. With recent advances in Generative Adversarial Networks (GANs), it becomes possible to generate realistic images in constrained domains. Our research aims at improving and better understanding GANs, as well as exploring alternative methods for image generation.
Learning generative models that can explain complex data distribution is a long-standing problem in machine learning research. At SE(3), we are particularly interested in image generation, which is extremely challenging due to the high dimensionality of data. Generative models of images are not only important for unsupervised feature learning, but also enable a wide range of commercial applications such as image editing. With recent advances in Generative Adversarial Networks (GANs), it becomes possible to generate realistic images in constrained domains. Our research aims at improving and better understanding GANs, as well as exploring alternative methods for image generation.
Video and Motion Analysis
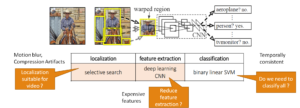 Video data understanding has drawn considerable interest in recent times as a result of access to huge amount of video data and success in image-based models for visual tasks. However, motion blur, compression artifacts cause apparently consistent video signals to produce high temporal variation on frame-level output for vision tasks such as object detection or semantic segmentation. In this project, we study efficient early, and high-level visual processing algorithms on videos by leveraging consistencies over time and space.
Video data understanding has drawn considerable interest in recent times as a result of access to huge amount of video data and success in image-based models for visual tasks. However, motion blur, compression artifacts cause apparently consistent video signals to produce high temporal variation on frame-level output for vision tasks such as object detection or semantic segmentation. In this project, we study efficient early, and high-level visual processing algorithms on videos by leveraging consistencies over time and space.
Subcategories in this field includes:
Object Detection in Video
Semantic Segmentation in Video
Supervoxel Segmentation
Musical Instrument Retrieval in Video
Fine-Grained Categorization
 Fine-grained categorization, as a sub-field of object recognition, aims to distinguish subordinate categories within entry level categories. Examples include recognizing species of birds such as “northern cardinal” or “indigo bunting”; flowers such as “tulip” or “cherry blossom”. Fine-grained categorization often requires efforts from different aspects compared with generic object recognition.
Fine-grained categorization, as a sub-field of object recognition, aims to distinguish subordinate categories within entry level categories. Examples include recognizing species of birds such as “northern cardinal” or “indigo bunting”; flowers such as “tulip” or “cherry blossom”. Fine-grained categorization often requires efforts from different aspects compared with generic object recognition.
At SE(3), we are mainly interested in three fundamental problems of fine-grained categorization: 1) building large-scale, high-quality datasets for benchmarking fine-grained categorization methods; 2) designing algorithms that are more suitable for fine-grained recognition tasks; 3) exploring ways to bring human’s expertise into fine-grained categorization.
Crowdsourcing
 Crowdsourcing is the practice of collecting data directly from humans. This is useful for projects where human expertise is needed. Challenges in this space include creating worker environments that are pleasant to use and that respect our crowd workers’ skill, asking questions in the most cost-effective ways, selecting the most informative questions to ask workers that maximize the information gain per cost, and finding/eliminating spam to ensure high quality without throwing away legitimate work.
Crowdsourcing is the practice of collecting data directly from humans. This is useful for projects where human expertise is needed. Challenges in this space include creating worker environments that are pleasant to use and that respect our crowd workers’ skill, asking questions in the most cost-effective ways, selecting the most informative questions to ask workers that maximize the information gain per cost, and finding/eliminating spam to ensure high quality without throwing away legitimate work.